Парадокс цифровой эпохи
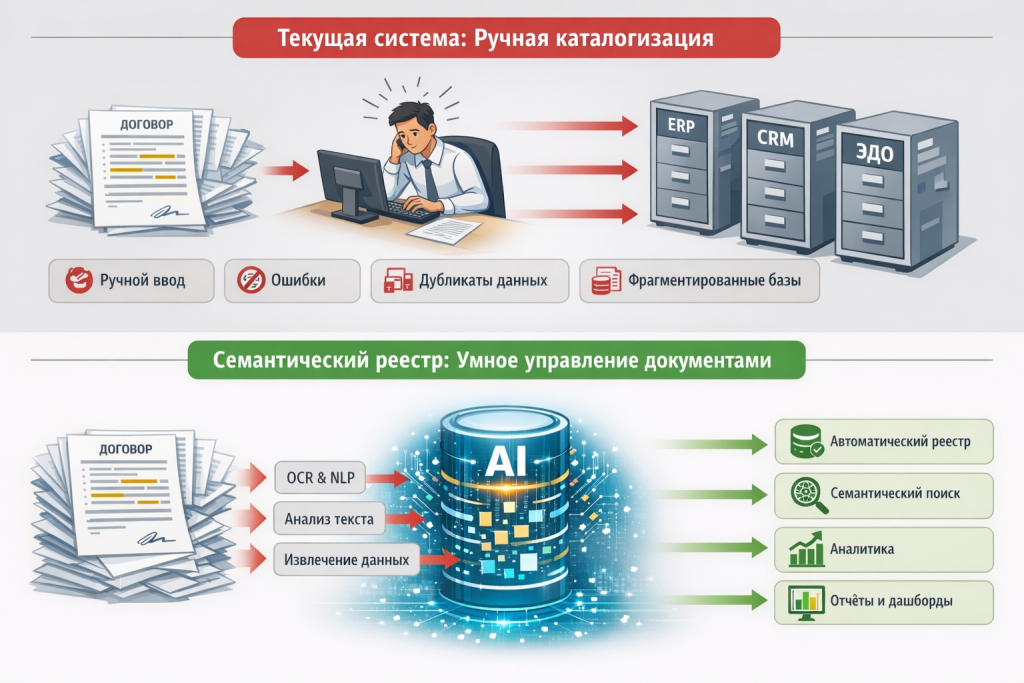
Большинство средних и крупных компаний прошли через волну цифровизации. Внедрены ERP-системы, развёрнуты электронные архивы, настроены CRM-платформы. Тем не менее в операционной практике воспроизводится один и тот же сценарий: сотрудник получает подписанный договор, открывает учётную систему и начинает вручную переносить в неё данные — наименование контрагента, сумму, сроки, реквизиты. Те самые данные, которые уже зафиксированы в документе. Это не частная проблема отдельной компании и не вопрос недостаточной автоматизации, а структурный изъян, встроенный в логику традиционных учётных систем: они проектировались под хранение атрибутов, а не под работу с содержанием. Разрыв между тем, что реально написано в договоре, и тем, что попадает в базу данных, – это и есть ключевая точка потерь: финансовых, временных, аналитических.
Почему традиционные системы учёта исчерпали себя
Архитектурное ограничение карточки
Системы класса 1С, SAP или типовые ERP строятся вокруг концепции «карточки объекта»: набора фиксированных полей, которые описывают сущность — договор, контрагента, актив. Такая модель была оправдана в эпоху, когда вычислительные мощности были ограничены, а задача сводилась к структурированному хранению данных для последующей отчётности.
Проблема в том, что карточка по определению является упрощением. Она фиксирует лишь те атрибуты, которые разработчик или методолог посчитал важными в момент проектирования системы. Всё остальное содержимое документа – формулировки условий, оговорки, нестандартные положения остаётся за пределами системы, существуя только в виде прикреплённого файла, который никто системно не обрабатывает.
Когда бизнес-задача выходит за рамки стандартной отчётности, например, нужно выявить все договоры с правом одностороннего расторжения или найти контракты, где валюта платежа привязана к курсу, – традиционная система оказывается бесполезной. Ответа на такой вопрос в её структурированных полях попросту нет.
Человеческий фактор как системный риск
Ручной ввод данных – это не просто трудозатраты. Это постоянно действующий источник ошибок, неполноты и рассогласованности. Опечатка в ИНН контрагента, некорректно указанная дата окончания договора, пропущенный дополнительный лимит ответственности – каждая такая ошибка потенциально влечёт за собой последствия: от неверных управленческих решений до претензий и судебных разбирательств. Показательно, что проверить достоверность внесённых данных в большинстве организаций можно только одним способом – вернуться к оригиналу документа и сверить вручную. То есть система, призванная избавить от работы с бумагой, фактически требует постоянного обращения к ней.
Стоимость сопровождения, которую принято не замечать
Совокупная стоимость владения процессом ручного ввода и поддержания реестров в актуальном состоянии, как правило, не рассчитывается явно – она размазана по фонду оплаты труда, затратам на исправление ошибок и потерям от упущенных рисков. Если провести такой расчёт честно, включив время юристов на внесение данных, время бухгалтеров на сверку, время руководителей на поиск нужных договоров, цифра оказывается неожиданно значительной.
Платформенный феодализм
Второй структурный изъян – фрагментация корпоративного IT-ландшафта. Исторически сложилось так, что автоматизация в большинстве организаций шла не по единому плану, а по принципу «закрыть ближайшую боль»: внедрили бухгалтерию, потом отдельно CRM, потом систему электронного документооборота. Каждая из этих систем решает свою задачу, но данные в них живут изолированно.
Результат предсказуем: один и тот же контрагент существует в трёх системах с тремя разными написаниями наименования. Договор числится в СЭД как исполненный, в CRM – как активный, а в 1С по нему продолжают начисляться обязательства. Попытки синхронизировать эти данные через интеграционные шины и API-коннекторы, как правило, оказываются дороже и трудоёмче, чем предполагалось на этапе проектирования, — и никогда не дают стопроцентной согласованности, потому что источники расхождений воспроизводятся снова и снова на уровне ручного ввода. Это и есть «платформенный феодализм»: у каждой системы свои правила, своя модель данных, своя зона влияния. Единой картины операционной деятельности не существует – она всякий раз собирается вручную в Excel накануне совещания.
Семантический реестр: в чём принципиальное отличие
Смена первичного источника
Ключевое концептуальное изменение в семантическом подходе состоит в следующем: первичным источником данных становится не человек, вносящий атрибуты, а сам текст документа, из которого данные извлекаются автоматически.
Это меняет всю логику процесса. Документ перестаёт быть «вложением к карточке» и становится самостоятельным информационным активом, с которым система умеет работать содержательно. OCR-движок переводит сканы и PDF в машиночитаемый текст. Языковая модель анализирует этот текст и извлекает структурированные сущности: стороны договора, суммы, сроки, условия расторжения, штрафные санкции, специальные оговорки. Векторизация создаёт смысловое представление документа, которое позволяет находить его по контексту, а не только по точному совпадению ключевых слов.
Что такое векторный индекс и почему это важно
Для понимания семантического поиска важно разобраться с механизмом. Традиционный поиск работает как сопоставление строк: система ищет документы, в которых встречается введённое слово или фраза. Это работает хорошо, когда вы точно знаете, что ищете, и помните точную формулировку.
Семантический поиск устроен иначе. Каждый документ преобразуется в числовой вектор – математическое представление его смысла в многомерном пространстве. Документы с близким содержанием оказываются «рядом» в этом пространстве, даже если в них используются совершенно разные слова. Это позволяет задавать запросы на естественном языке и получать релевантные результаты даже при отсутствии точных совпадений: «договоры с условиями об автоматической пролонгации» найдут контракты, где это условие сформулировано десятками разных способов.
Аналитика, которая была невозможна
Семантический реестр открывает класс задач, которые традиционными системами в принципе не решаются:
Мониторинг обязательств. Система автоматически отслеживает приближение ключевых дат – не только сроков окончания договоров, но и контрольных точек, опционов, дедлайнов по уведомлениям. Ничего не теряется между папками на сетевом диске.
Выявление рисков в формулировках. Юридически значимые условия – ограничения ответственности, основания для одностороннего расторжения, валютные оговорки могут быть выявлены и сопоставлены по всей договорной базе. Это та работа, которую раньше мог сделать только опытный юрист вручную, просматривая каждый договор.
Сравнительный анализ условий. Насколько условия нового договора отличаются от стандартных? Какие контрагенты получили нестандартные скидки на штрафные санкции? Подобные вопросы перестают требовать многочасового ручного анализа.
Поиск противоречий. Система способна обнаруживать внутренние противоречия – когда условия одного договора конфликтуют с рамочным соглашением или когда дополнительное соглашение фактически отменяет положение, на которое ссылается другой документ.
Архитектура перехода: как это работает на практике
Реализация семантического реестра опирается на несколько технологических слоёв, каждый из которых решает свою задачу.
Слой захвата документов отвечает за приём входящих документов в любом формате – PDF, DOCX, сканированные изображения и их первичную обработку. OCR-движки (такие как Tesseract или коммерческие решения) обеспечивают распознавание текста с достаточным качеством для последующего анализа.
Слой извлечения структурированных данных использует языковые модели для идентификации и извлечения ключевых сущностей. Здесь важен не просто факт нахождения числа или даты, но понимание контекста: это сумма договора или сумма штрафных санкций? Это дата подписания или дата вступления в силу? Оркестраторы типа LangChain позволяют выстроить многоэтапные цепочки обработки, где каждый шаг верифицирует результаты предыдущего.
Слой семантической индексации строит векторные представления документов и обеспечивает их хранение в специализированных векторных базах данных. Именно этот слой обеспечивает возможность смыслового поиска.
Слой аналитики и интерфейсов предоставляет пользователям доступ к накопленным данным через понятные интерфейсы – от простого поиска на естественном языке до настраиваемых дашбордов с мониторингом ключевых показателей:
| Характеристика | Традиционный подход | Семантический подход |
| Источник данных | Ручной ввод | Текст документа |
| Полнота информации | Ограничена полями карточки | Полный контекст документа |
| Тип поиска | Точное совпадение | Смысловое соответствие |
| Обнаружение рисков | Вручную, периодически | Автоматически, непрерывно |
| Согласованность данных | Зависит от дисциплины ввода | Единый источник – документ |
| Аналитические возможности | Стандартная отчётность | Произвольные смысловые запросы |
Реалистичный взгляд на внедрение
Было бы неточно представлять семантические реестры как готовое решение, которое достаточно развернуть и оно заработает само. Несколько практических ограничений заслуживают честного разговора.
Качество входных документов. Языковая модель работает ровно настолько хорошо, насколько хорошо она может прочитать текст. Плохо отсканированные документы, нестандартные шрифты, рукописные правки на полях – всё это снижает точность извлечения. Инвестиции в качество документооборота на входе напрямую влияют на качество аналитики на выходе.
Необходимость валидации. Автоматическое извлечение данных не означает стопроцентную точность. Для юридически значимых атрибутов необходим процесс валидации, при котором система помечает извлечённые данные как «требующие проверки» до подтверждения ответственным сотрудником. Это не дублирует старый процесс ввода – верификация существенно быстрее первичного ввода, но снимает иллюзию полной автоматизации там, где она преждевременна.
Работа с историческим архивом. Перевод существующей договорной базы в семантический реестр – это отдельный проект с собственными временными и ресурсными затратами. Как правило, разумнее начинать с новых документов, выстраивая процесс на перспективу, а не пытаться немедленно обработать весь архив за последние десять лет.
Управление изменениями. Техническое внедрение – меньшая часть проблемы. Большая состоит в перестройке рабочих процессов и, что важнее, в изменении привычек сотрудников. Люди, годами вносившие данные по определённому регламенту, не автоматически начинают доверять системе, которая делает это за них.
Кейс: статистика Белстата и ловушка ручной аналитики
Когда данных много, а ответов нет
Представим типичную ситуацию. Белстат регулярно (ежемесячно, ежеквартально, ежегодно) публикует обновления: десятки Excel-файлов, сгруппированных по тематическим разделам. Занятость, ВВП, промышленное производство, демография, внешняя торговля. Каждый раздел – отдельная папка. Каждая папка – свой набор файлов. Каждый файл – своя логика оформления. Организация, которой эти данные нужны для работы, назначает ответственного. Назовём его аналитиком, хотя в реальности это может быть экономист, плановик или специалист по стратегии. Этот человек получает очередной пакет файлов и приступает к работе, которая на первый взгляд выглядит как рутина, а на самом деле является структурной проблемой всей организации.
Файлы Белстата не приходят в виде аккуратной таблицы с единым форматом. Это живые документы государственной статистики: объединённые ячейки, многоуровневые заголовки, сноски с методологическими оговорками, итоговые строки, встроенные в середину данных. Названия показателей от периода к периоду могут незначительно меняться — потому что изменилась методика расчёта, расширилась выборка или была пересмотрена классификация.
Чтобы встроить новый пакет данных в существующую сводную базу, аналитику нужно: разобраться в структуре каждого нового файла, сопоставить текущие названия показателей с теми, что были в прошлом периоде, принять решения о том, как обработать несоответствия, вручную перенести данные в сводную таблицу и проверить результат. На это уходит от нескольких часов до нескольких рабочих дней – при каждом цикле обновления, из квартала в квартал, из года в год.
Знания хранятся в голове одного человека
Сводная база, которую ведёт аналитик, – это не просто файл. Это накопленная экспертиза: решения о том, как сопоставить показатели за разные периоды, как обработать методологические разрывы, какие данные считать сопоставимыми, а какие – нет. Эти решения нигде формально не задокументированы. Они существуют в голове конкретного человека и частично – в структуре его Excel-файла, которую посторонний человек не может интерпретировать без объяснений. Последствия этого очевидны руководителю, который хоть раз сталкивался с уходом ключевого аналитика: база остаётся, знания уходят. Новый сотрудник тратит месяцы на то, чтобы понять логику предшественника или начинает всё заново, создавая параллельную версию с собственными допущениями.
Каждый запрос – отдельная работа
Когда руководителю нужна конкретная таблица – динамика производительности труда по отраслям, сравнение показателей занятости по регионам, индексы потребительских цен в разбивке по товарным группам – запрос поступает к аналитику. Тот открывает базу, фильтрует нужные данные, собирает таблицу, форматирует, отправляет. Через неделю приходит уточнение: «А можно добавить ещё один год и разбить по кварталам?» Процесс повторяется. Аналитик становится узким горлышком между данными и теми, кто принимает решения на их основе. Его рабочее время тратится не на интерпретацию и выводы, а на механическую сборку таблиц.
Методологический контекст теряется безвозвратно
Файлы Белстата содержат не только цифры, но и пояснения: определения показателей, изменения в методике расчёта, территориальные исключения, особенности выборки. При ручном переносе данных в сводную базу эти пояснения, как правило, не переносятся – они остаются в исходных файлах, которые со временем вытесняются новыми версиями или просто теряются в глубине архива. В результате база содержит цифры без контекста. Когда через два года кто-то замечает нетипичный скачок показателя и спрашивает «почему здесь такое значение?» – ответа в базе нет. Нужно возвращаться к исходникам и искать объяснение вручную. Если исходники не сохранились – объяснения нет вовсе.
Момент, когда всё усугубляется: платформенный проект
Описанная ситуация – неудобная, но терпимая, пока организация работает в устоявшемся режиме. Настоящий кризис наступает тогда, когда возникает решение о построении цифровой платформы — аналитической системы, портала данных или инструмента поддержки принятия решений.
В этот момент выясняется несколько вещей одновременно.
Базу нельзя просто «подключить». Разработчики платформы ожидают структурированный источник данных с формальной схемой, описанными связями между показателями и предсказуемым форматом обновлений. Вместо этого они получают Excel-файл, логика которого понятна только его автору. Начинается процесс «перевода» – и он занимает значительно больше времени, чем предполагалось.
Допущения, сделанные на этапе проектирования, оказываются неверными. Разработчики закладывают в архитектуру платформы определённые предположения о структуре данных. Когда начинается реальная загрузка, выясняется, что часть показателей несопоставима между периодами, часть данных отсутствует, часть – задублирована с разными названиями. Исправление этих ошибок на поздних этапах разработки стоит непропорционально дорого.
Проблема воспроизводится на новом уровне. Даже если первичная загрузка данных в платформу проходит успешно, процесс регулярных обновлений остаётся нерешённым. Каждый новый пакет от Белстата по-прежнему требует ручной обработки перед тем, как попасть в платформу. Автоматизация верхнего уровня (красивый интерфейс, визуализации, дашборды) не решает проблему нижнего уровня — неструктурированного источника данных.
Место семантического реестра
Семантический реестр в данном сценарии – это не замена аналитику и не альтернатива платформе. Это промежуточный слой, который решает конкретную проблему: превращает неструктурированный поток файлов от Белстата в управляемый, нормализованный и воспроизводимый источник данных.
Практически это выглядит следующим образом. Входящие файлы Белстата поступают в систему и автоматически обрабатываются: структура таблиц распознаётся, показатели извлекаются и нормализуются, методологические пояснения сохраняются как связанный контекст, а не отбрасываются. Изменения в названиях показателей между периодами фиксируются и разрешаются через словарь соответствий, который система ведёт и пополняет.
Аналитик при этом не устраняется из процесса – он смещается. Вместо того чтобы тратить день на разбор структуры нового файла, он тратит час на верификацию результатов автоматической обработки. Его экспертиза используется там, где она действительно нужна: в оценке качества данных и их интерпретации, а не в механическом переносе цифр из одной таблицы в другую.
Запросы от руководства обслуживаются напрямую: пользователь формулирует потребность на естественном языке, система находит релевантные показатели и собирает таблицу. Аналитик получает время на то, чтобы объяснить, что стоит за цифрами, – а это и есть та работа, за которую платят.
Риски изменений
Было бы нечестно описывать переход к семантическому реестру как безболезненный процесс. У него есть реальные сложности, и руководителю лучше понимать их до начала проекта, а не в процессе.
Формализация неявных знаний – это трудоёмко. Вся накопленная логика работы с данными, которая сейчас хранится в голове аналитика, должна быть извлечена, описана и закреплена. Это требует времени и готовности аналитика к сотрудничеству. В организациях, где ключевой специалист воспринимает свою незаменимость как конкурентное преимущество, этот шаг может встретить пассивное сопротивление.
Исторический архив – это отдельный проект. Обработка накопленных за годы файлов – не автоматическая операция. Она требует разового вложения ресурсов, причём значительного. Практичнее начинать с новых поступлений и выстраивать правильный процесс на перспективу, оставив историческую миграцию на второй этап с реалистичными оценками трудозатрат.
Доверие к автоматическому извлечению формируется постепенно. Руководители, привыкшие к тому, что данные верифицируются человеком, поначалу будут скептически относиться к результатам автоматической обработки. Это нормально. Процесс валидации на начальном этапе должен быть прозрачным и задокументированным не для того чтобы имитировать старый процесс, а для того чтобы сформировать обоснованное доверие к новому.
Регламент обновлений требует организационного решения. Технологический инструмент не работает сам по себе. Кто отвечает за запуск обработки при поступлении нового пакета от Белстата? Кто верифицирует результаты? Как фиксируются решения об обработке методологических изменений? Без ответов на эти вопросы система превратится в ещё один инструмент, который формально есть, но фактически не используется.
Проблема, описанная в этом кейсе, не решается наймом более дисциплинированного аналитика или переходом на более продвинутый Excel. Она встроена в логику процесса: данные поступают в формате, не предназначенном для машинной обработки, и единственным инструментом их «перевода» является ручной труд квалифицированного специалиста. Семантический реестр меняет эту логику. Он не устраняет необходимость в экспертизе – он освобождает её от работы, которая экспертизы не требует. А для платформенного проекта он решает более фундаментальную задачу: превращает неформализованный источник данных в архитектурно пригодный фундамент, на котором можно строить.
Заключение
Если отвлечься от технологий и посмотреть на происходящее честно, картина выглядит примерно так: организации десятилетиями инвестировали в цифровизацию и в результате получили очень дорогие инструменты для хранения данных, которые по-прежнему требуют человека, чтобы в них что-то положить, и другого человека, чтобы оттуда что-то достать. ERP не победила Excel. Она просто добавила ещё один экран, между которым и Excel сидит сотрудник с копипастом.
Семантический реестр интересен не как технология, а как диагноз. Сам факт того, что подобный подход сегодня становится практически реализуемым, означает одно: всё то время, пока организации вручную переносили данные из документов в карточки, они платили не за автоматизацию. Они платили за имитацию автоматизации. За системы, которые выглядели как решение, но оставляли самую трудоёмкую часть работы людям – просто переместив её с бумаги на клавиатуру.
Переход к семантическому управлению данными – это не апгрейд. Это запоздалое исправление архитектурной ошибки, заложенной ещё на этапе проектирования первых учётных систем. Ошибки, за которую организации продолжают платить каждый месяц – просто не видят этого в платёжной ведомости.
Те, кто это увидят раньше других, получат не просто более удобный инструмент. Они получат другое качество управленческого зрения: способность задавать вопросы, на которые раньше не было ответа – не потому что данных не существовало, а потому что они были заперты в файлах, которые никто системно не читал.
Система создана не для того, чтобы люди работали в ней. Она должна работать вместо людей.
![]()